Context
This project is a research workbench for experimenting with ARC-style game-playing agents. It is not a finished solver. The goal is to make it easy to compare agent designs, inspect behavior, and produce reproducible artifacts while iterating.
What I built
I set up the repo as a shared framework rather than a one-off bot.
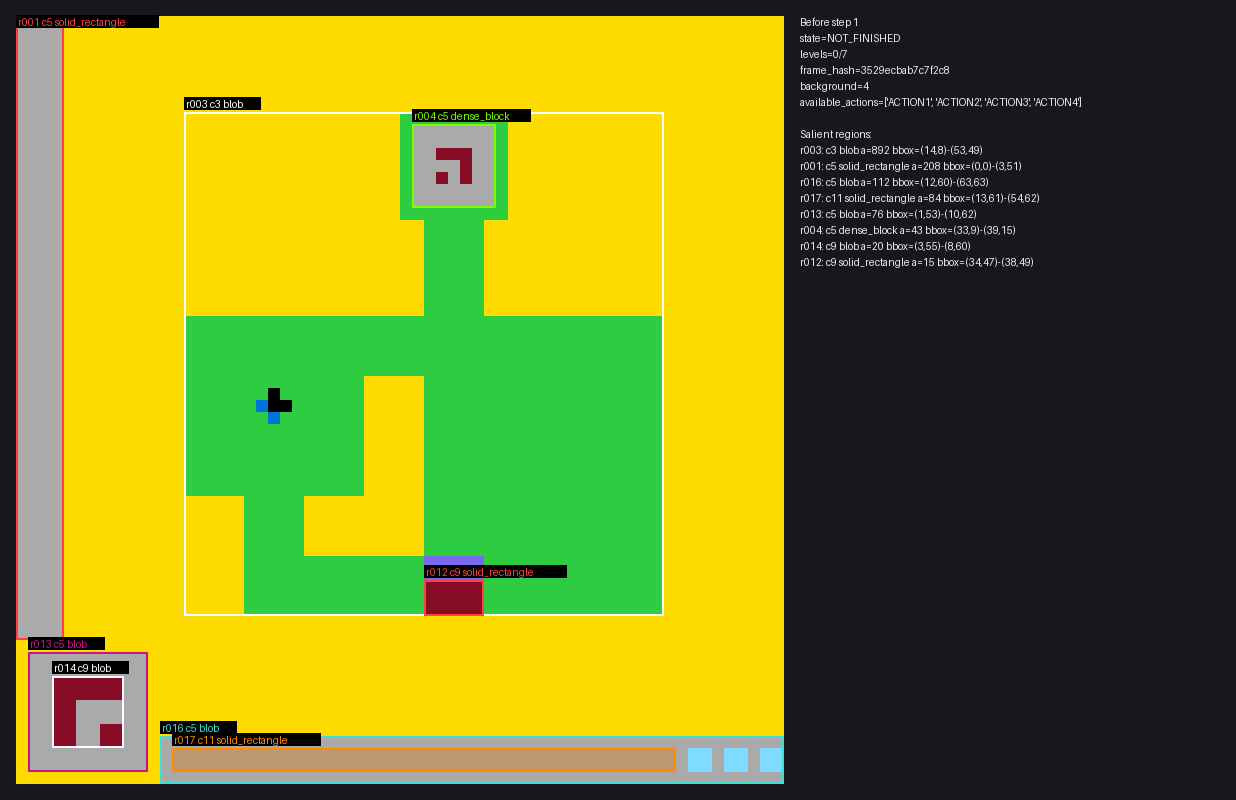
A debug snapshot from the evaluation loop before the agent acts.
- Plugin-style bot discovery so new agents can be added without rewriting a central registry
- A CLI and benchmark flow for running the same tasks across different agents
- Debug tooling for stepping through agent behavior and transition history
- Artifact generation so each run leaves behind summaries, transitions, and diagnostics
Technical ideas
One part I particularly liked was the evaluation design. Instead of only asking whether a level was solved, I added a prediction-first loop that scores agents on exact next-state matches and per-cell accuracy.
The repo also builds structured board summaries using connected components, dominant colors, changed regions, and transition diffs so agents can reason about richer descriptions than raw grids alone.
Result
The current state is intentionally honest: it is a research prototype, not a solved benchmark. Some agents already make strong short-horizon predictions, but turning that into reliable task completion is still the hard part.
That makes the project valuable because it captures the infrastructure and evaluation work needed before stronger agent behavior can emerge.
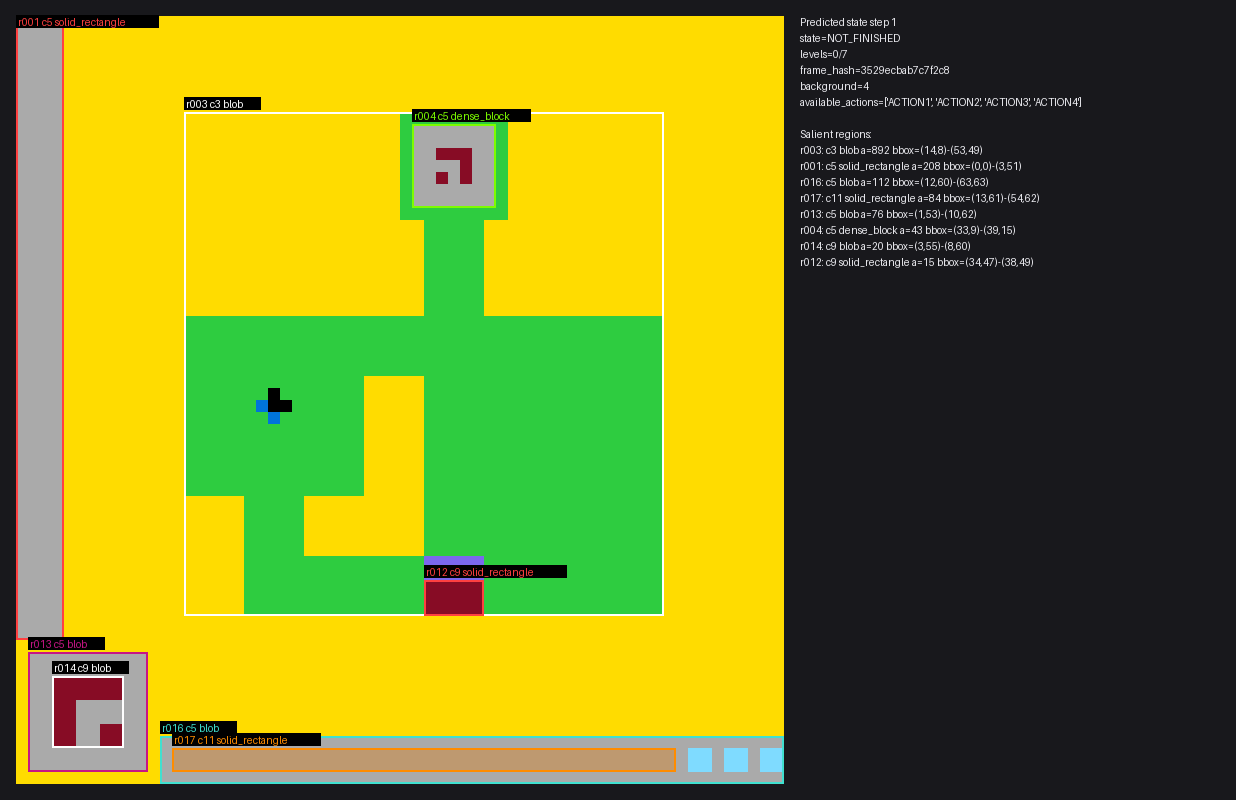
The framework records predicted states as artifacts so agent reasoning can be evaluated directly instead of only looking at success or failure.
Why this framing matters
I built the evaluation loop this way because success or failure alone hides too much information. Prediction quality, transition summaries, and saved artifacts make it much easier to see whether an agent is learning the environment or just stumbling through it.